算法简介
KNN(K-Nearest Neighbor)算法是机器学习算法中最基础、最简单的算法之一。它既能用于分类,也能用于回归。KNN通过测量不同特征值之间的距离来进行分类。
KNN算法的思想非常简单:对于任意n维输入向量,分别对应于特征空间中的一个点,输出为该特征向量所对应的类别标签或预测值。
kNN的思想
# 首先导入必要的包和训练集数据
import numpy as np
import matplotlib.pyplot as plt
# 导入训练集(良性/恶性肿瘤)
raw_data_x=[[3.393533211,2.331273381],
[3.110073483,1.781539638],
[1.343808831,3.368360954],
[3.582294042,4.679179110],
[2.280362439,2.866990263],
[7.423436942,4.696522875],
[5.745051997,3.533989803],
[9.172168622,2.511101045],
[7.792783481,3.424088941],
[7.939820817,0.791637231]
]
# 0代表良性肿瘤、1代表恶性肿瘤
raw_data_y=[0,0,0,0,0,1,1,1,1,1]
X_train = np.array(raw_data_x)
Y_train = np.array(raw_data_y)
# 这里将良性肿瘤标记为绿色,将恶性肿瘤表标记为红色
plt.scatter(X_train[Y_train==0,0],X_train[Y_train==0,1],color='g')
plt.scatter(X_train[Y_train==1,0],X_train[Y_train==1,1],color='r')
plt.show()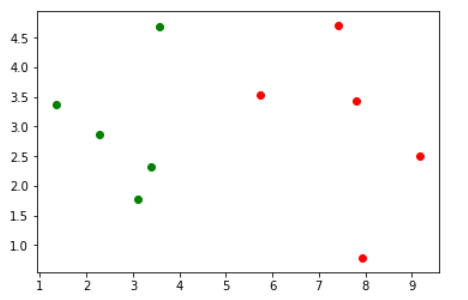
假设现在有一个点的数据,需要知道属于恶性肿瘤或者是良性肿瘤,先把这个点描绘出来。
# 绘制新点
x=np.array([8.093607318,3.365731514])
plt.scatter(X_train[Y_train==0,0],X_train[Y_train==0,1],color='g')
plt.scatter(X_train[Y_train==1,0],X_train[Y_train==1,1],color='r')
# 将这个点标记为蓝色
plt.scatter(x[0],x[1],color='b')
plt.show()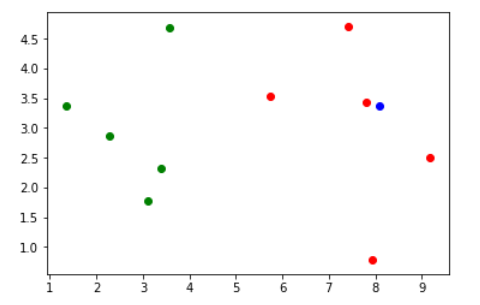
假设取和蓝点距离最近的三个点,此处的距离我们取的是欧拉距离
$$ \sqrt { \sum _ { i = 1 } ^ { n } \left( X _ { i } ^ { ( a ) } - X _ { i } ^ { ( b ) } \right) ^ { 2 } } $$
取与这个蓝点欧拉距离最小的三个点,让这些点进行投票,如上图,离蓝点最近的3个点都是红点,那么投票结果就是3:0,预测这个蓝点为恶性肿瘤。
代码实现
不使用scikit-learn框架的实现
# 此处引用上面测试集的数据以及预测点的数据
from math import sqrt
distances = []
for x_train in X_train:
d = sqrt(np.sum((x_train - x)**2 ))
# 计算欧拉距离
distances.append(d)
# 也可使用Python自带的列表生成表达式写法,效果是一样的
distances = [sqrt(np.sum((x_train - x)**2 )) for x_train in X_train
# distances如下
#[4.812566907609877,
# 5.229270827235305,
# 6.749798999160064,
# 4.6986266144110695,
# 5.83460014556857,
# 1.4900114024329525,
# 2.354574897431513,
# 1.3761132675144652,
# 0.3064319992975,
# 2.5786840957478887]
# 距离从小到大的索引值
nearest = np.argsort(distances)
# array([8, 7, 5, 6, 9, 3, 0, 1, 4, 2], dtype=int64)
# 定义kNN的k为6
k=6
# 取欧拉距离最近的6个点lable
topK_y = [Y_train[i] for i in nearest[:k]]
# [1, 1, 1, 1, 1, 0]
from collections import Counter
votes = Counter(topK_y)
# 取出投票最多的一个元素
predict_y = votes.most_common(1)[0][0]
# 1
# 上面的1即为预测结果使用Scikit-learn中的kNN
# 导入kNN分类器
from sklearn.neighbors import KNeighborsClassifier
# 新建kNN分类器对象
kNN_classifier = KNeighborsClassifier(n_neighbors=6)
# 导入训练集
kNN_classifier.fit(X_train,Y_train)
# KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
# metric_params=None, n_jobs=None, n_neighbors=6, p=2,
# weights='uniform')
# 注意此处如果直接使用 kNN_classifier.predict(x) 会报错
X_predict = x.reshape(1,-1)
# array([[8.09360732, 3.36573151]])
y_predict = kNN_classifier.predict(X_predict)
y_predict[0]
# 1
# 上面即为预测结果封装自己的kNN算法
import numpy as np
from math import sqrt
from collections import Counter
class KNNClassifier:
def __init__(self, k):
"""初始化kNN分类器"""
assert k >= 1, "k must be valid"
self.k = k
self._X_train = None
self._y_train = None
def fit(self, X_train, y_train):
"""根据训练数据集X_train和y_train训练kNN分类器"""
assert X_train.shape[0] == y_train.shape[0], \
"the size of X_train must be equal to the size of y_train"
assert self.k <= X_train.shape[0], \
"the size of X_train must be at least k."
self._X_train = X_train
self._y_train = y_train
return self
def predict(self, X_predict):
"""给定待预测数据集X_predict,返回表示X_predict的结果向量"""
assert self._X_train is not None and self._y_train is not None, \
"must fit before predict!"
assert X_predict.shape[1] == self._X_train.shape[1], \
"the feature number of X_predict must be equal to X_train"
y_predict = [self._predict(x) for x in X_predict]
return np.array(y_predict)
def _predict(self, x):
"""给定单个待预测数据x,返回x的预测结果值"""
assert x.shape[0] == self._X_train.shape[1], \
"the feature number of x must be equal to X_train"
distances = [sqrt(np.sum((x_train - x) ** 2))
for x_train in self._X_train]
nearest = np.argsort(distances)
topK_y = [self._y_train[i] for i in nearest[:self.k]]
votes = Counter(topK_y)
return votes.most_common(1)[0][0]
def __repr__(self):
return "KNN(k=%d)" % self.k超参数
什么是模型超参数?
机器学习中的模型参数和模型超参数在作用、来源等方面都有所不同。模型参数是模型内部的配置变量,可以用数据估计模型参数的值;模型超参数是模型外部的配置,必须手动设置参数的值。
模型超参数是模型外部的配置,其值不能从数据估计得到,具体特征有:
- 模型超参数常应用于估计模型参数的过程中。
- 模型超参数通常由实践者直接指定。
- 模型超参数通常可以使用启发式方法来设置。
- 模型超参数通常根据给定的预测建模问题而调整。
怎么设置模型超参数
对于给定的问题,我们无法知道模型超参数的最优值。但我们可以使用经验法则来探寻其最优值,或复制用于其他问题的值,也可以通过反复试验的方法
例子
- 训练神经网络的学习速率。
- kNN算法中的k
- 支持向量机的C和sigma超参数。
kNN算法中的超参数
超参数k
在上面的示例中,k的值都是由我们自己手动设定,由k设置的不同,模型的准确率也不同,那么k取多少的时候,能够得到最优解呢?
# 寻找最好超参数k的值
digits = datasets.load_digits()
X=digits.data
y=digits.target
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size = 0.2, random_state = 666)
best_score= 0.0
best_k = -1
for k in range(1,11):
knn_clf = KNeighborsClassifier(n_neighbors=k)
knn_clf.fit(X_train,y_train)
score = knn_clf.score(X_test,y_test)
if score > best_score:
best_k = k
best_score = score
print('best_k = ',best_k)
print('best_score = ',score)
# best_k = 4
# best_score = 0.9833333333333333是否考虑距离
在上面的实现过程中,最终的预测结果是按照最邻近k个点的投票结果得出,这样存在一个问题:假设与预测点距离最小的3个点中,有2个是B结果,有1个是A结果,但是预测点与A结果的点距离很近,这里假设是0.01,那么预测的结果就明显有问题了;同时还存在另外一种情况,k个点投票的结果可能会出现平票的情况。
为了解决上面的两种情况,我们应该考虑将距离作为投票的权重。在scikit-learn中,向KNeighborsClassifier传入参数weights=distance即可将距离作为投票的权重
best_method = ''
best_score = 0.0
best_k = -1
for method in ["uniform","distance"]:
for k in range(1,11):
knn_clf = KNeighborsClassifier(n_neighbors=k,weights=method)
knn_clf.fit(X_train,y_train)
score = knn_clf.score(X_test,y_test)
if score > best_score:
best_k = k
best_score = score
best_method = method
print('best_method = ',best_method)
print('best_k = ',best_k)
print('best_score = ',score)
# best_method = uniform
# best_k = 4
# best_score = 0.9861111111111112使用哪个距离
需要注意的是,无论是在之前的示例中,还是scikit-learn中kNN分类器中使用weights=distance,都是计算两个点之前的欧拉距离。
同样的,我们也可以使用其他公式计算距离,例如曼哈顿距离$\left.\left(\sum_{i=1}^{n} | X_{i}^{(a)}-X_{i}^{(b)}\right\rceil\right)^{\frac{1}{1}}$
和闵可夫斯基距离$\left(\sum_{i=1}^{n}\left|X_{i}^{(a)}-X_{i}^{(b)}\right|^{p}\right)^{\frac{1}{p}}$,这两个公式在形式上与欧拉距离$\left(\sum_{i=1}^{n}\left|X_{i}^{(a)}-X_{i}^{(b)}\right|^{2}\right)^{\frac{1}{2}}$具有形式一致性。
观察可知,当p取1时,为曼哈顿距离;当p取2时,为欧拉距离;当p取其他整数时,为闵可夫斯基距离。由此可知,可以将p作为另一个超参数。
# 搜索超参数p的最佳值
%%time
# 搜索闵可夫斯基距离相应的p
best_score = 0.0
best_k = -1
best_p = -1
for k in range(1,11):
for p in range(1,6):
# 如果搜索p,则weights要使用distance
knn_clf = KNeighborsClassifier(n_neighbors=k,weights="distance",p=p)
knn_clf.fit(X_train,y_train)
score = knn_clf.score(X_test,y_test)
if score > best_score:
best_k = k
best_score = score
best_p = p
print('best_p = ',p)
print('best_k = ',best_k)
print('best_score = ',score)
# best_p = 5
# best_k = 3
# best_score = 0.9833333333333333
# Wall time: 18.6 s使用网格搜索(grid search)得到最佳的超参数
# 定义网格
param_grid=[
{
'weights':['uniform'],
"n_neighbors":[i for i in range(1,11)]
},
{
'weights':['distance'],
'n_neighbors':[i for i in range(1,11)],
'p':[i for i in range(1,6)]
}
]
knn_clf = KNeighborsClassifier()
from sklearn.model_selection import GridSearchCV
grid_search = GridSearchCV(knn_clf,param_grid)
grid_search.fit(X_train,y_train)
grid_search.best_estimator_
# KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
# metric_params=None, n_jobs=None, n_neighbors=1, p=2,
# weights='uniform')
grid_search.best_score_
# 0.9860820751064653
grid_search.best_params_
# {'n_neighbors': 1, 'weights': 'uniform'}此外,grid search默认只调用一个cpu进行运算,可以使用n_jobs参数使用多个核心进行运算,提高运行效率。

